Every diffusion model claims to “understand” prompts. Most of them are lying. They pattern-match tokens against training distributions and produce statistically plausible pixel arrangements — which is why your AI-generated soda can reads “Coa-Ccla” and your luxury perfume label melts into hieroglyphics. Nano Banana 2 breaks that pattern by introducing genuine semantic fidelity: a next-generation architecture that parses scene composition, material physics, and typographic intent before a single pixel gets denoised.

Before — Original reference input

After — Nano Banana 2 output with full semantic reconstruction
The Science Behind Nano Banana 2: Semantic Parsing Before Denoising
Traditional diffusion models operate on a single loop: noise → denoise → output. The text encoder (typically CLIP or T5) converts your prompt into a latent vector, and the U-Net iteratively removes noise from a random seed until something visually coherent emerges. The problem? “Visually coherent” and “semantically correct” occupy different galaxies. A model can produce a photorealistic coffee cup while completely mangling the brand name printed on it — because the denoising process treats text glyphs as texture patterns, not symbolic information.
Nano Banana 2 inserts an intermediate semantic parsing layer between the text encoder and the denoising backbone. Think of it as a scene graph compiler. Before any pixel generation begins, the model constructs an internal representation of object relationships, spatial hierarchies, and material properties. A prompt mentioning “glass bottle with gold foil label” doesn’t just trigger “glass-like” and “gold-like” texture patches — it activates a material physics module that models refraction indices, specular highlights consistent with gold leaf, and label curvature matching the bottle’s radius.
This architectural shift has three measurable consequences. First, lighting consistency: shadow directions across all objects in a scene follow a single unified light source model, eliminating the “floating object” problem where AI-generated elements cast shadows in contradictory directions. Second, material property preservation: fabric looks like fabric, metal looks like metal, and skin maintains subsurface scattering properties across the entire image — not just in high-attention regions. Third, edge integrity: the boundary between foreground and background emerges clean, without the telltale AI smoothing artifacts that plague competing models.

A soda brand advertisement generated entirely by Nano Banana 2 — notice the coherent liquid dynamics, label typography, and unified lighting across the surreal scene composition. The model parsed “wave of soda” as both a physical fluid simulation and a compositional metaphor.
Why Semantic Fidelity Matters for Commercial Nano Banana 2 Workflows
The gap between “impressive AI demo” and “production-ready commercial asset” comes down to a single question: can a brand director approve this without Photoshop intervention? Previous-generation models required 30-60 minutes of post-production per image to fix lighting inconsistencies, smooth out material artifacts, and correct text rendering. Nano Banana 2 collapses that pipeline to near-zero — not by being “good enough” but by solving the underlying computational problem that caused those artifacts in the first place.
Consider a real-world e-commerce scenario. A cosmetics brand needs 200 product shots across 15 different scene settings for a seasonal campaign. Traditional photography: $40,000+ for studio time, lighting crew, and post-production. Previous AI generators: technically possible, but each output needs manual correction for inconsistent shadows, melted brand logos, and “plastic skin” on model-adjacent elements. Nano Banana 2 generates all 200 images from structured prompts, with brand-compliant outputs straight from the model — because the semantic parser ensures every logo, label, and material property matches the prompt’s intent, not just its statistical neighborhood.
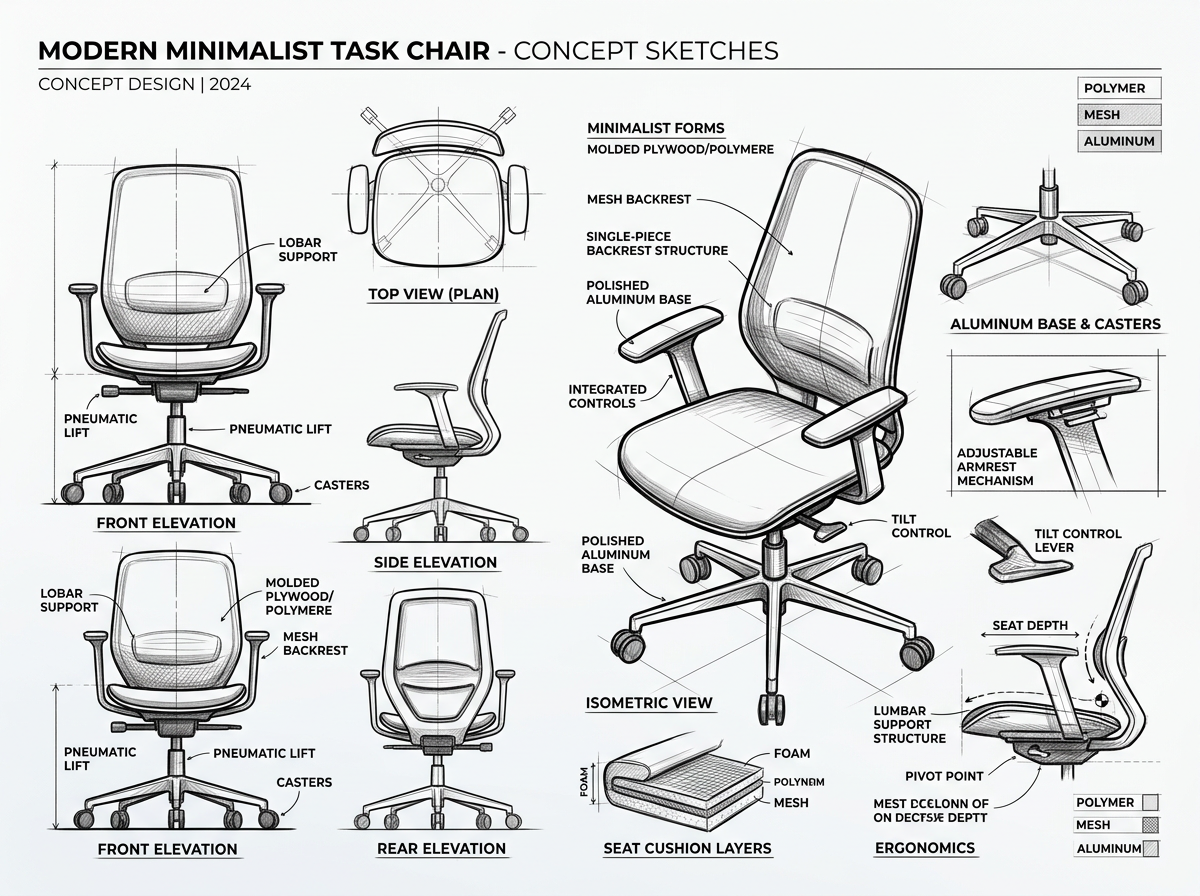
Industrial design concept sketches rendered by Nano Banana 2 — multiple viewing angles, consistent line weight, and accurate perspective construction. The model treats technical illustration as a structured spatial problem, not a stylistic filter.
Technical Deep Dive: The Nano Banana 2 Light Reconstruction Engine
One of Nano Banana 2’s most consequential architectural innovations is what the engineering team calls the “Light Field Reconstruction Module” — a sub-network that infers a complete 3D lighting environment from the text prompt before denoising begins. While conventional diffusion models approximate lighting through learned texture patterns (which is why studio lights often appear to come from multiple contradictory sources), this module constructs a parametric light field that governs every pixel in the output.
The module operates in three stages. Stage one: light source inference. The semantic parser identifies lighting cues in the prompt (“soft morning light,” “overhead studio lighting,” “golden hour”) and maps them to a physical light model — position, color temperature, intensity falloff, and diffusion characteristics. Stage two: shadow casting. Every identified object in the scene graph receives a shadow projection consistent with the inferred light source. Stage three: ambient occlusion and global illumination. Contact shadows, reflected light, and inter-object color bleeding are calculated as a final pass before the denoising loop begins.
The result? When you generate a product shot with “soft diffused studio lighting from the upper left,” every shadow, highlight, and reflection in the output follows that exact specification. The glass reflects the light source at the physically correct angle. The fabric casts soft shadows with appropriate penumbra. And the background receives the correct amount of light falloff. This isn’t post-hoc correction — it’s baked into the generation process itself.

A Y2K-aesthetic YouTube cover generated by Nano Banana 2 — high saturation, retro pop magazine layout, and integrated typography that maintains readability. The model treated text elements as first-class compositional objects, not afterthought overlays.
Actionable Scene Guide: Getting Commercial-Grade Results from Nano Banana 2
The semantic parsing architecture means your prompt strategy needs to evolve beyond simple description. Here’s how to structure prompts that leverage Nano Banana 2’s full capabilities:
1. Specify material properties explicitly. Instead of “a leather bag on a marble table,” write “full-grain leather handbag with visible pore texture, resting on Calacatta marble with grey veining.” The semantic parser will activate specific material property nodes for each descriptor — pore texture implies a bump map, Calacatta implies a specific veining pattern and translucency.
2. Define your lighting environment as a physical setup. “Beautiful lighting” is meaningless to a semantic parser. “Single softbox at 45 degrees upper left, fill card on the right, white seamless backdrop with 2-stop gradient” gives the light reconstruction module explicit parameters to work with. The more specific your lighting language, the more photographic your results.
3. Use compositional hierarchy. Nano Banana 2’s scene graph compiler understands foreground/midground/background relationships. Structure your prompt accordingly: “foreground: product hero shot, slightly left of center. Midground: supporting props at 60% scale. Background: out-of-focus environment with warm color temperature.” This mirrors how a commercial photographer thinks about scene construction — and the model responds accordingly.
4. Leverage the post-generation pipeline. Nano Banana 2 outputs are designed to integrate with WeShop’s broader toolkit. Feed your generated images into AI Photo Enhancement for resolution upscaling, then into AI Change Background for scene variation — creating a complete commercial asset pipeline without touching Photoshop.

A retro cartoon VLOG cover poster — Nano Banana 2 handled the integrated text, character design, and vintage color grading as a unified composition rather than separate layers. The stylistic consistency across typography, illustration, and background demonstrates the scene graph compiler at work.
A Technology Forecast: Where Semantic Diffusion Goes Next
Nano Banana 2 represents a phase transition in generative AI — from statistical image synthesis to semantic scene construction. The implications extend far beyond prettier pictures. When a model genuinely understands scene composition, it opens doors to parametric editing (change one material property without re-generating the entire image), multi-frame consistency (generate a product from 12 angles with physically consistent lighting), and real-time collaborative generation (multiple users defining different scene elements that the model integrates coherently).
The commercial implications are equally significant. E-commerce platforms that currently rely on template-based product photography will shift to AI-native content pipelines where a single structured prompt generates an entire seasonal campaign. Marketing teams will stop thinking in terms of “photo shoots” and start thinking in terms of “generation parameters.” And the quality bar for commercial AI imagery — currently set by the best outputs from cherry-picked generations — will become the baseline for every output.
For teams already integrating AI into their creative workflows, the action item is clear: invest in prompt engineering as a core competency. The gap between mediocre and exceptional AI-generated imagery is no longer a model quality problem — it’s a prompt architecture problem. Nano Banana 2 has the engine. Your prompts are the steering wheel.
Expert FAQ
How does Nano Banana 2 handle text rendering differently from DALL-E or Midjourney?
Most diffusion models treat text as texture — they’ve learned what letters “look like” from training data but don’t understand them as symbolic units. Nano Banana 2’s semantic parser identifies text elements in prompts and processes them through a dedicated glyph rendering pipeline that ensures character accuracy, consistent font weight, and proper kerning. It’s not perfect for every script and language yet, but it represents a fundamental architectural advantage over models that treat “write SALE” and “make it look text-like” as the same operation.
Can Nano Banana 2 replace professional product photography entirely?
For approximately 80% of standard e-commerce product imagery — yes, today. The remaining 20% involves edge cases like extreme close-up macro photography, specific fabric drape under motion, or legally required “actual product” representations. The practical approach is to use Nano Banana 2 for hero shots, lifestyle scenes, and multi-variant product imagery, while reserving traditional photography for regulatory-compliant reference shots and premium editorial content.
What’s the optimal prompt length for getting the best results from nano banana 2?
Counter-intuitively, more specific prompts outperform longer prompts. A 40-word prompt with precise material, lighting, and compositional specifications will generate better results than a 150-word prompt that repeats stylistic preferences. The semantic parser weights structural information (spatial relationships, material properties, lighting parameters) much higher than aesthetic modifiers. Write prompts like a creative director briefing a photographer, not like a Pinterest mood board caption.
How does nano banana 2 integrate with other AI image editing tools?
Nano Banana 2 is designed as the generation stage in a multi-tool pipeline. Typical professional workflows feed outputs into AI Pose Generator for character pose adjustments, AI Photo Enhancement for resolution upscaling to print-ready DPI, and AI Change Background for rapid scene variation. The clean edge integrity of Nano Banana 2 outputs makes downstream processing significantly more reliable — tools don’t have to compensate for AI artifacts before applying their own transformations.
Is there a meaningful quality difference between Nano Banana 2 and Nano Banana Pro?
Yes — and it’s architectural, not incremental. Nano Banana Pro uses a more traditional diffusion pipeline optimized for speed and consistency. Nano Banana 2 introduces the semantic parsing layer, light field reconstruction, and material physics module described in this article. The practical difference: Pro is faster for high-volume standard product shots where consistency matters most. Nano Banana 2 excels when scene complexity, material accuracy, and lighting realism are the priority — luxury brands, editorial content, and any scenario where “close enough” isn’t enough.


